Approach
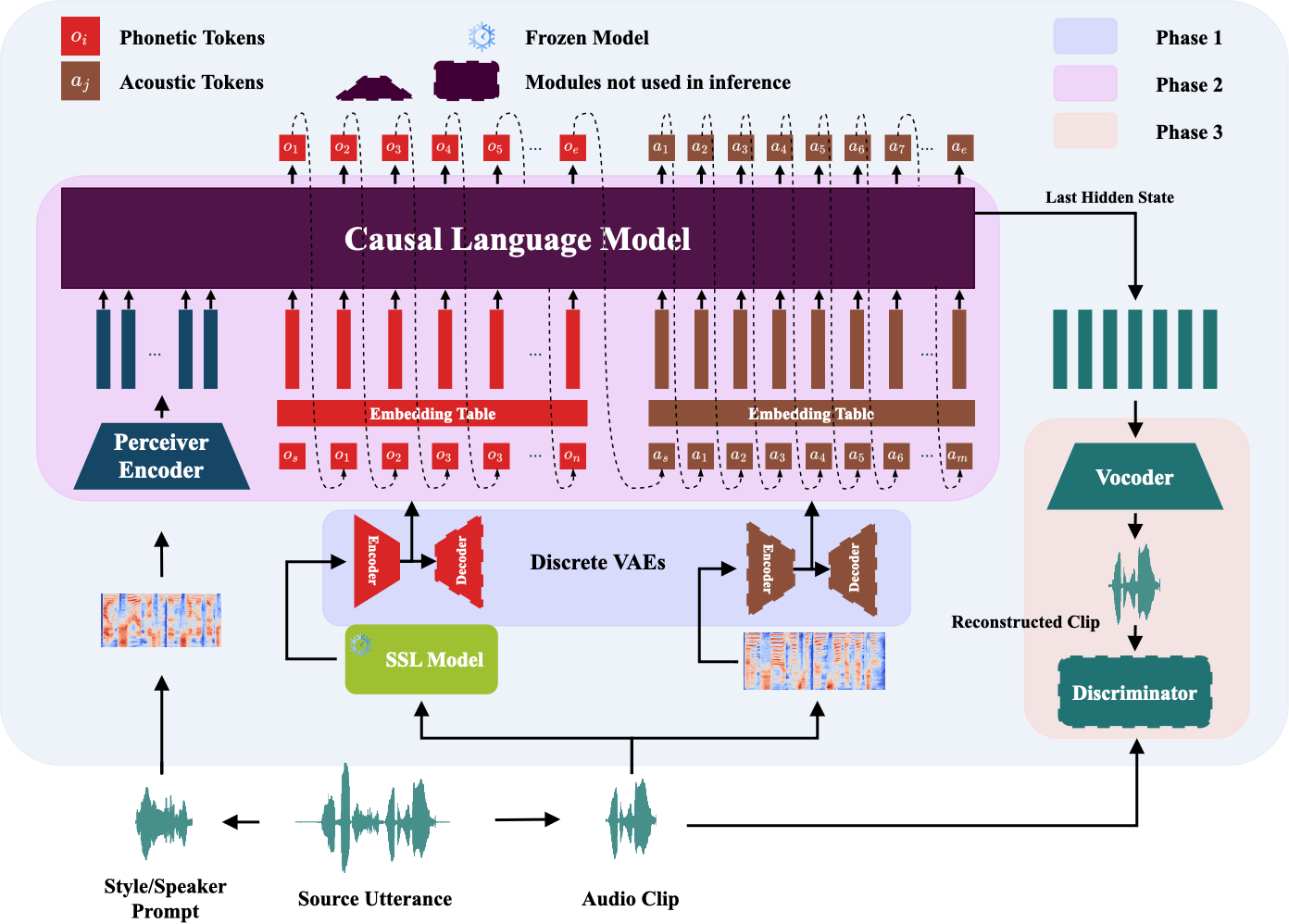
Large Language Models (LLMs) have shown strong performance in low-resource offline translation; however, extending them to simultaneous speech-to-speech translation (Simul-S2ST) remains challenging due to lack of causally aligned, speaker-preserving data. In addition, existing approaches rely on fixed translation policy or confidence heuristics, leading to suboptimal quality and higher latency. We propose a causality-aware Simul-S2ST framework with a novel data pipeline that generates high-fidelity, causally aligned segments with voice preservation. The framework further proposes (i) a factorized S2ST architecture (FAST), (ii) a causality-aware adaptive policy (CAP), and (iii) alignment-aware latency metric. Experiments on CVSS (Spanish, German, and French) show that FAST improves translation by up to +9.6 ASR-BLEU over shared codec-based representations, while CAP gains up to +5.5 ASR-BLEU and reduces latency by 26% compared to fixed policy.
| Source Utterance | Target Prompt | Leading VC Approaches | GenVC | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
|
|
|
||||||||||||
| |
|
|
|
||||||||||||
| |
|
|
|
||||||||||||
| |
|
|
|
||||||||||||
| |
|
|
|
||||||||||||
| |
|
|
|
@misc{cai2025genvcselfsupervisedzeroshotvoice,
title={GenVC: Self-Supervised Zero-Shot Voice Conversion},
author={Zexin Cai and Henry Li Xinyuan and Ashi Garg and Leibny Paola García-Perera and Kevin Duh and Sanjeev Khudanpur and Matthew Wiesner and Nicholas Andrews},
booktitle={IEEE Workshop on Automatic Speech Recognition and Understanding},
year={2025},
volume={},
number={},
pages={},
}